peng_imb3 <- prep_penguins_multiclass_imbalance(
minority_class = "Chinstrap",
hard_to_class = "Adelie",
n_minority = 15L
)
peng_imb3 |>
count(y3) |>
knitr::kable(col.names = c("Species", "n"))| Species | n |
|---|---|
| Adelie | 146 |
| Gentoo | 119 |
| Chinstrap | 15 |
Minimal walkthrough for Day 4 Part E: three-species classification with a rare Chinstrap class, one model, and step_upsample() in the recipe.
See also three-species notebook and the Palmer Penguins data card.
We keep Adelie and Gentoo abundant and retain 15 Chinstrap rows (deterministic rule: closest to the Adelie morphometric cloud).
peng_imb3 <- prep_penguins_multiclass_imbalance(
minority_class = "Chinstrap",
hard_to_class = "Adelie",
n_minority = 15L
)
peng_imb3 |>
count(y3) |>
knitr::kable(col.names = c("Species", "n"))| Species | n |
|---|---|
| Adelie | 146 |
| Gentoo | 119 |
| Chinstrap | 15 |
peng_imb3 |>
count(y3) |>
ggplot(aes(y3, n, fill = y3)) +
geom_col(show.legend = FALSE) +
geom_text(aes(label = n), vjust = -0.25, size = 4) +
theme_minimal() +
labs(title = "Class counts (rare Chinstrap)", x = NULL, y = "n")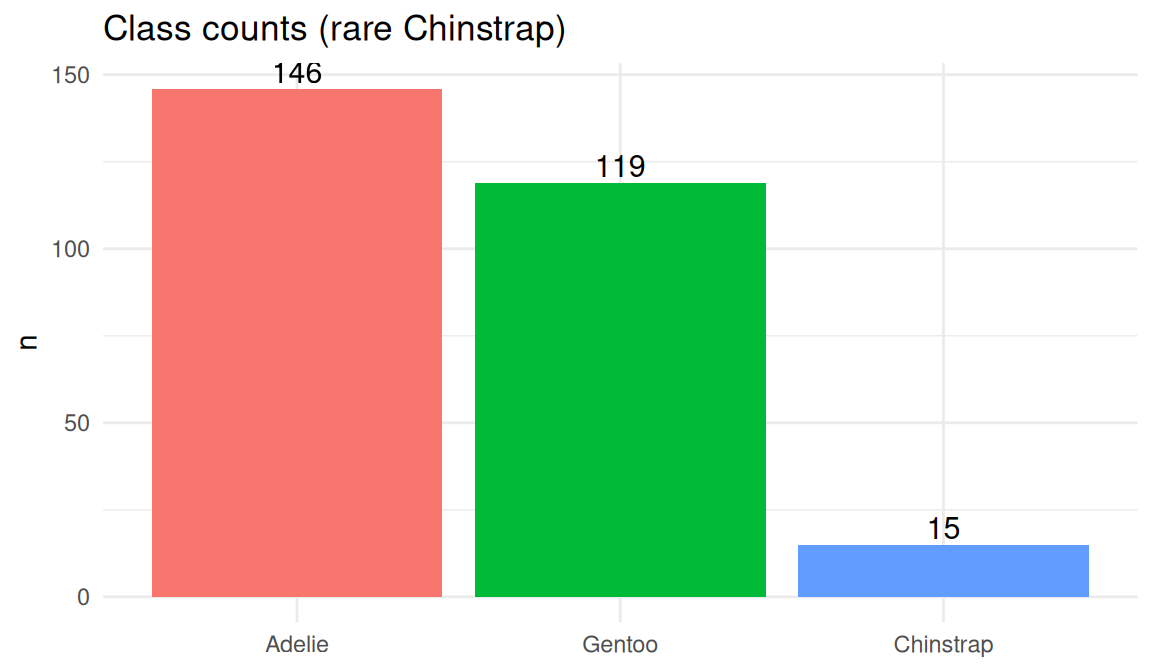
Same decision_tree spec; only the recipe differs (with vs without upsampling).
mc_tree_spec <- decision_tree(tree_depth = 4, min_n = 20) |>
set_engine("rpart") |>
set_mode("classification")
rec_no <- recipe(y3 ~ ., data = peng_imb3) |>
step_zv(all_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_normalize(all_numeric_predictors())
rec_up <- recipe(y3 ~ ., data = peng_imb3) |>
step_upsample(y3) |>
step_zv(all_predictors()) |>
step_dummy(all_nominal_predictors()) |>
step_normalize(all_numeric_predictors())
wf_no <- workflow() |> add_recipe(rec_no) |> add_model(mc_tree_spec)
wf_up <- workflow() |> add_recipe(rec_up) |> add_model(mc_tree_spec)set.seed(13)
split <- initial_split(peng_imb3, prop = 0.8, strata = y3)
train <- training(split)
test <- testing(split)
fit_no <- fit(wf_no, train)
fit_up <- fit(wf_up, train)
pred_no <- augment(fit_no, test)
pred_up <- augment(fit_up, test)Rows = true species; columns = predicted species.
No upsampling:
pred_no |>
conf_mat(truth = y3, estimate = .pred_class) Truth
Prediction Adelie Gentoo Chinstrap
Adelie 30 0 3
Gentoo 0 23 0
Chinstrap 0 1 0With step_upsample(y3):
pred_up |>
conf_mat(truth = y3, estimate = .pred_class) Truth
Prediction Adelie Gentoo Chinstrap
Adelie 30 0 2
Gentoo 0 23 0
Chinstrap 0 1 1bind_rows(
multiclass_recall_table(pred_no, truth_col = "y3") |> mutate(model = "No upsample"),
multiclass_recall_table(pred_up, truth_col = "y3") |> mutate(model = "Upsample")
) |>
mutate(recall = round(recall, 3)) |>
select(model, truth, recall) |>
tidyr::pivot_wider(names_from = model, values_from = recall) |>
knitr::kable(caption = "Holdout recall by species")| truth | No upsample | Upsample |
|---|---|---|
| Chinstrap | 0.000 | 0.500 |
| Adelie | 0.909 | 0.938 |
| Gentoo | 1.000 | 1.000 |
Focus on the Chinstrap row: upsampling is useful when it raises minority recall without hiding poor performance on other classes.